
4.9 Ratings based on 1,000+ reviews
Empowering financial and quantitative companies with smarter, scalable AI data.
Redefining how institutions understand risk and behavior.
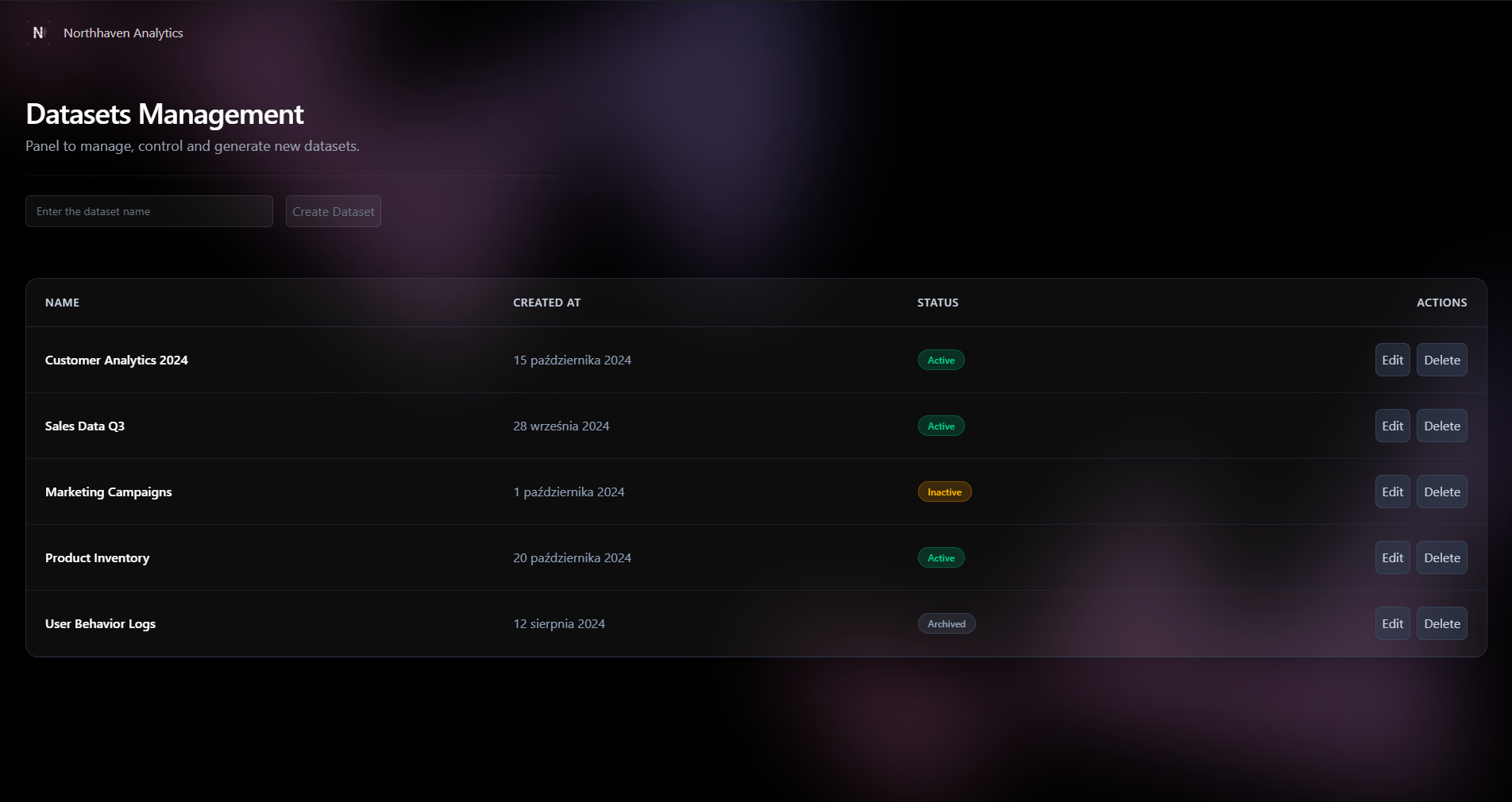
Features & Benefits
Why Institutions Choose Northhaven
We combine quantitative precision, regulatory alignment, and robust data engineering to help financial organisations operate on reliable, privacy-safe datasets. Our approach is built for teams that require accuracy, transparency, and institutional-grade performance.
Quant-Driven Data Engineering
Our datasets are not random outputs — they follow real economic structure, multivariate dependencies, and domain-specific constraints. Every file is built to behave like real financial systems.
Compliance-Safe by Design
We eliminate privacy risks at the architectural level. All datasets are synthetic, reproducible, and aligned with GDPR, PSD2 and internal audit requirements — ready for enterprise deployment.
Transparent, Verifiable Methodology
Each delivery includes documentation, metadata, validation metrics, and reproducibility controls. Institutions can inspect, audit, and integrate our data with full confidence.
Tailored for Financial Use-Cases
From credit scoring and risk modeling to fraud analytics and market behavior simulation — we build datasets specifically for the logic, scale, and constraints of the financial sector.
How Northhaven Enhances Your Financial Infrastructure
We provide institutions with high-fidelity synthetic datasets, advanced validation frameworks, and secure data engineering services built for quantitative research, risk modeling, and AI deployment. Our solutions help financial organisations accelerate model development, reduce compliance risk, and operate on data that is realistic, reproducible, and fully privacy-safe.
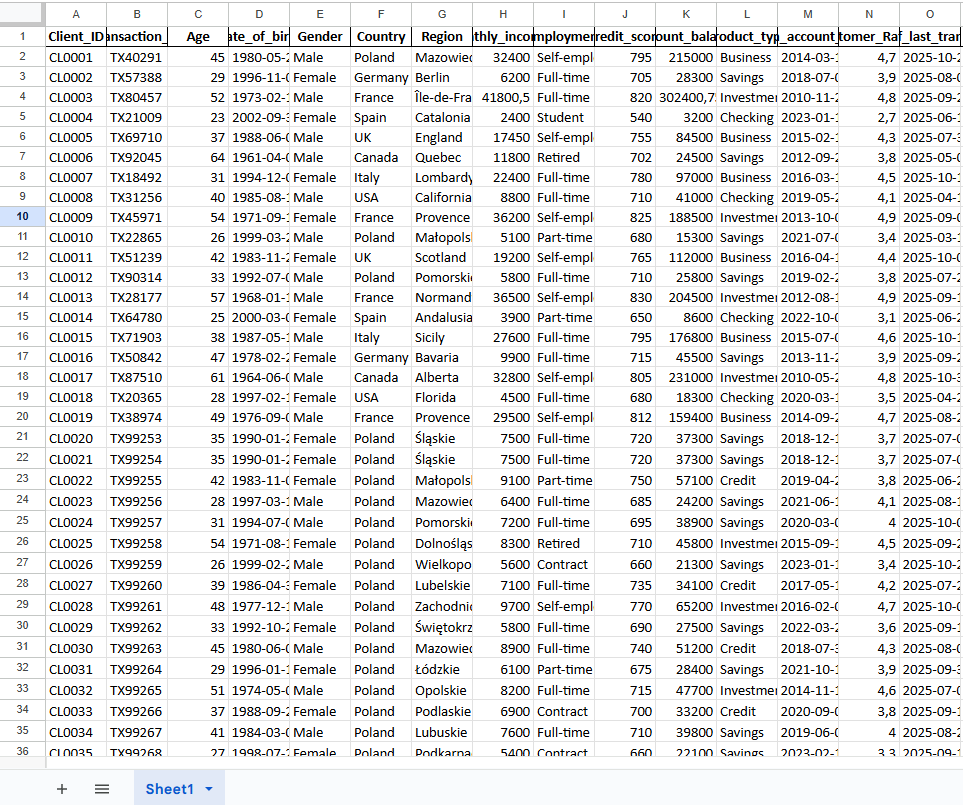
Synthetic financial datasets
We create realistic, correlation-aware datasets for credit scoring, risk modeling, transaction behavior, and market simulations. Each dataset is statistically consistent and tailored to specific business logic.
Custom model environments
For clients developing AI or quantitative models, we design isolated, synthetic training environments. These controlled data ecosystems reproduce real financial relationships without exposing sensitive information.
Data validation and advisory
Beyond generation, we provide validation frameworks that test model performance and dataset integrity. Our team supports financial institutions in integrating synthetic data safely into their analytical pipelines.
Latest insights
Explore our latest research, technical notes, and case studies on synthetic data and quantitative modeling. Every article reflects our work at the intersection of finance, data, and technology — written for those shaping the future of analytical intelligence.



Frequently Asked Questions
Frequently asked questions
Find clear answers to the most common questions about our synthetic data solutions, collaboration process, and data security standards. Whether you represent a bank, hedge fund, or research firm — this section explains how Northhaven Analytics helps you work smarter, safer, and faster.
How realistic are your synthetic datasets compared to real financial data?
Our datasets are not random simulations. Each is built using correlation matrices, behavioral logic, and domain-specific constraints. Variables like income, credit score, churn probability, and transaction flow are interdependent — meaning the data behaves statistically like real financial systems. On a model level, predictive accuracy typically matches 90–95% of the performance achieved with real-world data.
Can synthetic data really replace real client data for model training?
In many cases — yes. Synthetic data is ideal for model development, feature engineering, and risk testing. For final production calibration, real data is still useful, but synthetic environments allow teams to iterate faster, test edge cases, and reduce regulatory friction.
How is data privacy guaranteed if the datasets are synthetic?
We never access or transform client databases directly. Instead, our generation models are trained on structural metadata, not raw values. Each dataset is built from statistical patterns, ensuring no record or transaction can ever be traced back to a real person or institution.
What makes Northhaven Analytics different from other data generation platforms?
Most platforms focus on generic data — e-commerce, healthcare, or tabular simulations. We specialize exclusively in financial realism. Every dataset is constructed to reflect market logic, regulatory structures, and human behavior in finance. That’s what makes it usable for banks, hedge funds, and quantitative researchers.
Do you operate under NDAs and custom compliance requirements?
Always. Every collaboration starts with a mutual NDA. We adapt to each institution’s internal compliance rules and data handling policies. Our infrastructure is designed for secure delivery, auditability, and complete traceability of every generated dataset.
How long does it take to deliver a synthetic dataset?
It depends on complexity. Standard tabular datasets (e.g., credit risk or client behavior) can be delivered within 7–10 business days. Larger simulation environments with multi-table logic, correlations, and seasonality modeling may take up to 4–6 weeks.
Get in touch
Have a project in mind or want to explore how synthetic financial data can transform your research and risk modeling? Contact us for a free consultation — we’ll walk you through the process, discuss your data goals, and design a solution tailored to your institution.